
The secret of successful teaching of the ML model widely depends on data preprocessing. The data quality comprises consistency, completeness, and accuracy. As we know, to be provided for the ML analysis, collected raw data need special systematization. It may contain errors due to the initial entry of incorrect data, noise, or duplicates. There also can be problems with missing data values or inconsistencies in its codes. The record of reasons why the dataset may be poor is long and varied. Nevertheless, to eliminate all these reasons and make the data definite and reliable, a set of preprocessing techniques is used. Let’s take a deep look at every step in data preparation.
Step 1. Data cleaning

At this point we have three goals: to smooth the data, to fill the dataset with missing values, and to resolve the inconsistency. Implementation of data cleaning methods will make the dataset reliable and understandable by ML algorithms.
To smooth noisy data, we can use several methods. Binning method implies data sorting, classification, and division into bins.
Smoothing data can be realized by bin means, medians, boundaries, and so on. The clustering method involves outlier detection and removal. Another way to make it clear is to fit the noisy data into functions or carry out inspections by humans or computers.
Not every data has such an attribute as availability. To resolve the problem of missing data, we can utilize some solutions from ignoring to filling the missing value. But to receive a trustworthy outcome, we can use a decision tree or Bayes algorithms and fill the missing value with the most probable one.
A special meaning in its cleaning belongs to date format unification and data conversion from nominal to numeric format and vice versa. If you need a deeper understanding of the process, read this detailed explanation about ML data preparation.
Step 2. Data integration
It is about data combination from different sources into a consistent data warehouse. There are two issues concerning data integration.
The first problem is data entity identification. Metadata helps to identify attribute values relevant to the same database.
Another problem of data integration is data redundancy. Data abundance is rooted in the integration of various databases. For example, one attribute from different databases may have the same name or when the same dataset is located in several places. If you want to avoid data redundancy, you will have to delete useless data first. Then, it is significant to connect the values and build your own database. The next stage is data normalization which implies the production of clean data.
Step 3. Data transformation
It complies with several techniques. As we have mentioned in the first step, it is vital to smooth the data with the help of such methods as clustering, binning, or regression. Data aggregation is about summarizing and building a data cube model. Data generalization involves the replacement of raw data by processed one with the help of the hierarchy concept. Normalization is data scaling aimed at hitting into a particular range.
The common goal of all these techniques is to ensure an alternative data performance and receive a more predictive outcome.
Step 4. Data reduction
The warehouse of data may contain an enormous data volume. It is impossible to implement a fast data analysis. That is why it is essential to reduce data amount so that not to break data integrity. Data reduction suggests that part of primary data is cut down and arranged in a smaller amount.
There are some techniques useful in the process of reduction. For instance, data cube aggregation assists in the compilation and summarizing of information. Dimension is used for sorting and removing redundant data. Apart from this, a significant impact on data reduction has a compression of its size. A popular method of data compression is wavelet transform. This method implies coding or decoding digital information (videos, audio, and images). The method of numerosity reduction can be helpful in a parametric or non-parametric way. The first one implies the replacement of actual data with smaller ones with particular parameters, estimating and storage these parameters. The common methods of non-parametric techniques are clustering, samplings, or histograms.
Step 5. Data discretization
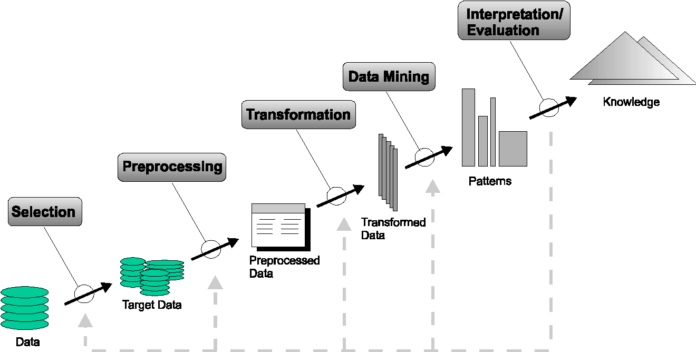
Discretization prepares the data for further analysis and makes it easy to manage it. The key idea of this method is to divide a wide range of data values and attributes into smaller pieces and create groups of data. It is vital for ML as it allows to recognize the similarities and create patterns. In this way, we can predict fraud, cancer, or potential consumer behavior.
Among discretization’s methods, we should mention a binning method, clustering, and histogram analysis. All these methods are universal. They are used in different stages of it processing.
The entropy-based method is typical for the discretization of ranking data. It makes data more exact. Another method is segmentation based on partitioning.
Data discretization techniques are aimed at generating concept hierarchy. By defining particular values of one attribute from a given data designs a hierarchy automatically.
Conclusion
So, taking everything into account we need to underline once again that developing efficient ML models depends on many factors. If we want our ML model to succeed, we will have to conduct a profound data preprocess.
Quality of data is vital. Understanding its roots, its fundamental principles of combination are also of great importance. Qualitative data is the guarantee of accurate prediction, made by ML algorithms.
The preparation of raw data takes a lot of time. It consists of a step-by-step strategy, including cleaning, integration, transformation, reduction, and discretization. There is a wide range of different preprocessing techniques, which helps to convert unclear data into easy to understand format. And we should admit that this data preprocessing is still exploring and studying. Data scientists and data mining specialists develop new approaches and offer new methodologies of data preprocessing so that to assure building accurate models in the machine learning and artificial intelligence field.






{kind=link}